FreePDF: Die Funktionen Scannen und OCR sind in FreePDF nicht enthalten.
Um Text zu bearbeiten, der nur als gescanntes Bild oder als Vektorgrafik vorliegt, müssen Sie zunächst die automatische Texterkennung (OCR) auf die betreffenden Seiten anwenden.
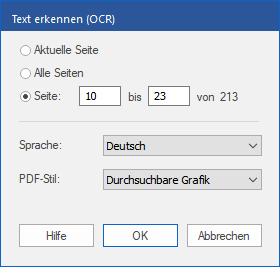
| 1. | Rufen Sie den Ribbonbefehl Seiten | Gruppe Texterkennung (OCR) | Text erkennen  auf. auf. |
| 2. | Wählen Sie die Seiten, die Sie verarbeiten möchten. |
| 3. | Wählen Sie die Sprache, in der der gescannte Text geschrieben ist. |
| 4. | Wählen Sie den gewünschten PDF-Stil: |
| Bearbeitbarer Text, wenn Sie den Text nach der automatischen Texterkennung sowohl betrachten als auch bearbeiten möchten. Dies erzeugt ein Dokument ohne Grafiken und Fotos, der Text kann jedoch wie gewohnt bearbeitet werden. |
| Durchsuchbare Grafik, wenn Sie das Layout der gescannten Seiten erhalten wollen. Der erkannte Text wird dann verborgen, ist aber für die Suche verfügbar. Sollten hierbei Fehler im Erkennungsprozess auftreten, können Sie diese mit den OCR-Korrekturen korrigiert werden. |
Anmerkungen
▪Die automatische Texterkennung wird nicht auf Seiten ausgeführt, auf denen sich bereits bearbeitbarer Text befindet, der also nicht mehr erkannt werden muss. Denn das Ergebnis könnte nie besser werden, sondern würde eher zu Verlusten an dem Text führen.
▪Wenn Sie die automatische Texterkennung lediglich auf einen Teil der Seite anwenden wollen, kopieren Sie diesen Teil in ein neues Dokument oder eine neue Seite und wenden Sie die automatische Texterkennung darauf an. Kopieren Sie das Ergebnis anschließend zurück an die ursprüngliche Stelle.