FreePDF: Die Funktionen Scannen und OCR sind in FreePDF nicht enthalten.
Wenn Ihr Computer Zugriff auf einen Scanner hat, können Sie diesen nutzen, um ein neues PDF aus einem Papierdokument zu erzeugen.
| 1. | Rufen Sie den Befehl Datei | Neu auf und wählen Sie Aus Scanner importieren. |
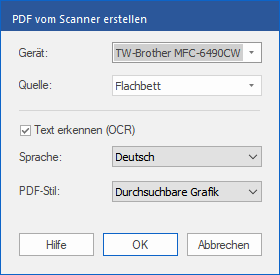
| Es erscheint folgendes Dialogfenster: |
| 2. | Wählen Sie Ihren Scanner aus der Liste Gerät. |
| Diese Liste wird anhand der auf Ihrem System installierten Geräte erstellt. |
| 3. | Verfügt Ihr Gerät über einen automatischen Dokumenteneinzug zum selbsttätigen Scannen mehrerer Seiten, können Sie diesen verwenden, indem Sie bei Quelle den Eintrag Automatischer Dokumenteneinzug wählen. |
| 4. | Um Wörter aus dem gescannten Dokument in bearbeitbaren oder durchsuchbaren Text zu konvertieren statt daraus lediglich eine "Fotografie" zu erstellen, vergewissern Sie sich, dass Text erkennen (OCR) angekreuzt ist. Wenn Sie ein Foto ohne Text scannen, aktivieren Sie diese Option nicht und überspringen Sie die nächsten Schritte. |
| 5. | Wählen Sie die Sprache des Textes des gescannten Dokuments. Das hilft FlexiPDF, die Wörter korrekt zu erkennen. |
| 6. | Wählen Sie den gewünschten PDF-Stil: |
| Bearbeitbarer Text, wenn Sie den Text nach der automatischen Texterkennung sowohl betrachten als auch bearbeiten möchten. Dies erzeugt ein Dokument ohne Grafiken und Fotos, der Text kann jedoch wie gewohnt bearbeitet werden. |
| Durchsuchbare Grafik, wenn Sie das Layout der gescannten Seiten erhalten wollen. Der erkannte Text wird dann verborgen, ist aber für die Suche verfügbar. Sollten hierbei Fehler im Erkennungsprozess auftreten, können Sie diese mit den OCR-Korrekturen korrigiert werden. |